A request from the TCP/IP model?
The Internet is a global computer network that consists of a set of networks. The whole system uses the same communication protocol: TCP/IP (Transmission Control Protocol / Internet Protocol). The Internet may still represent a new paradigm for some of us. All of a panoply of common physical acts are now happening online on the internet. Receiving or sending mail, making phone or video calls,… are works facilitated by Internet technologies. It is therefore important to know what is going on behind the scenes when you request a resource on the internet.
Screenplay:
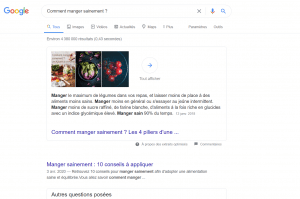
Nathalie wants to search for “how to eat healthy” on a search engine. It uses a computer connected to the Internet with a Google Chrome browser. She opens her browser and types in her question on Google. Nathalie wonders: so what happens when she presses the enter key on her computer?
In this article, I will answer Nathalie’s question by explaining step by step what happens.
Already, as I mentioned earlier, the Internet uses the TCP/IP communication protocol to transmit data. So what are TCP/IP models? (You can read my article on the TCP/IP vs ISO model to learn more)
TCP/IP
The TCP/IP suite, also known as the Internet protocol suite, is the set of protocols used to transfer data over the Internet. It is often called TCP/IP, after the names of its first two protocols: TCP (Transmission Control Protocol) and IP (Internet Protocol).
The TCP/IP model is a realistic or practical approach to a network model where the OSI model is an idealized or theoretical model. Consequently, the TCP/IP model is used as the reference network model for the Internet.
Step 1
First, when Nathalie hits the enter key after typing her question on the Google search bar. The first protocols used will be HTTP or HTTPS (HTTP + the TLS encryption protocol). HTTP will send Nathalie’s question as a request to Google’s server. In this case, the request will be “send me the requested HTML information”.
Step 2
Then, other protocols will be used such as DNS (converting www.google.com into the IP address of the Google server or to find the Google server), etc. The HTTP protocol allows you to create an HTTP request. This request (this data) will have to be transported through the networks.
Step 3
For this, the system will already have to use a transport protocol like TCP for example. This will guarantee the integrity of the data and the transmission between processes. At this level, in the transport layer, data from different processes are transformed into segments.
Step 4
Each segment contains the original data with a transport header attached. This header contains the port numbers of the source (Nathalie’s PC) and the destination (Google Server) so that the data can be transmitted effectively.
Step 5
These segments are then transmitted to the Internet layer protocols. The role of this layer is to choose the fastest route through the network for the data to reach its destination (at Google). The segments are then transformed into packages. This layer also takes care of addressing the data by adding a header to the packets that contains the destination IP address (Google’s IP) and the originating IP address (Nathalie’s IP).
Step 6
The packets are then transformed back into frames in the network access layer. At this level, a header is added containing the MAC (Media Access Control) addresses, which allow any device to be uniquely identified as source and destination.
Step 7
Finally, in this same layer, the information is finally transformed into bits (0 and 1 which correspond to the language of computers). And these bits are sent into the network (the 0’s and 1’s are encoded in the cables using electrical transmissions or light pulses in the case of fiber, via Nathalie’s network).
As soon as these bits arrive at their destination (at Google), their point of entry: the Google network. The operations then proceed in the opposite direction: The bits are reformed into frames, then into packets, into segments and finally the basic data are reconstituted.
However, it is important to understand how a search on Google works and how Google will manage, answer Nathalie’s question?

The functioning of Google is based on the principle of a gigantic database. Fed and constantly updated by robots. The robots analyze the web and index the pages they find. moving from one page to another by following the links contained in each page.
For each page found by the rebots, Google adds to its database the address of the page, the content of the page (title, text, image descriptions etc.). And links to other pages. It is this indexing that feeds the results displayed by the search engine.
For one query, there are thousands of web pages that contain potentially relevant information. In order to offer the best of them first, Google uses algorithms to evaluate their usefulness.
From search parameters to geographical location, including the user’s search history! All this information allows Google to propose the most relevant and useful results at the time.
Before presenting the results, Google evaluates the link between all the relevant information it has found. As the web evolves. Google adapts the ranking systems to return better quality results.